Dashboard 47 giây thành 0.3 giây migrate analytics từ Postgres sang ClickHouse
Câu chuyện thực tế về việc tách analytics workload ra khỏi Postgres, dựng pipeline CDC sang ClickHouse, và giảm thời gian load dashboard từ 47s xuống 0.3s.
Nguyễn Nhật Long
Nguồn: David Nguyen
Chắc anh em nào làm SaaS cũng từng gặp cái pha này: hệ thống chạy ngon lành vài tháng đầu, dashboard analytics load nhanh vèo vèo, ai cũng happy. Rồi đến một ngày đẹp trời, data tích lũy đủ nhiều, dashboard bắt đầu quay vòng vòng 30 giây, 40 giây, rồi gần phút. User complain, PM hỏi dồn, team dev ngồi EXPLAIN ANALYZE mà muốn khóc.
Mình vừa đi qua đúng bài toán này. Một hệ thống SaaS B2B, mỗi tenant có dashboard riêng, mỗi ngày phát sinh khoảng 1 triệu transaction. Sau 6 tháng vận hành, tổng dữ liệu đạt tầm 100 triệu dòng. Và cái dashboard tổng hợp doanh thu theo ngày tưởng chừng đơn giản nhất mất tới 47 giây để load. Mình sẽ kể lại toàn bộ quá trình từ lúc cố cứu Postgres, đến lúc quyết định tách analytics sang ClickHouse, và kết quả cuối cùng ra sao.
Postgres đã cố gắng hết sức rồi
Điều đầu tiên mình muốn nói rõ: team không hề bỏ cuộc sớm với Postgres. Chúng mình đã dành gần hai tuần để tuning đủ kiểu trước khi nghĩ đến chuyện migrate. Liệt kê ra thì gồm:
- Composite index trên các cột thường xuyên xuất hiện trong WHERE và GROUP BY
- Partition theo tháng bằng
pg_partman - Materialized view cho các query phổ biến nhất
- Tăng RAM lên 128GB để Postgres có thể cache nhiều hơn
- Tune
shared_buffers,work_mem,effective_cache_sizetheo best practice
Kết quả? Dashboard giảm từ 47 giây xuống... khoảng 20 giây. Nghe thì có vẻ cải thiện đáng kể, nhưng thực tế với một analytics product, dashboard 20 giây vẫn là unusable. User mở lên, chờ, rồi đóng tab. Bounce rate tăng, retention giảm. PM bảo "cải thiện thêm đi", nhưng mình biết đã chạm trần rồi.
Vấn đề cốt lõi không phải Postgres yếu. Postgres là một database cực kỳ mạnh cho đúng use-case của nó. Nhưng cái mình đang yêu cầu nó làm scan hàng chục triệu dòng, aggregate trên vài cột, group by theo thời gian đó là OLAP workload, và Postgres được thiết kế cho OLTP.
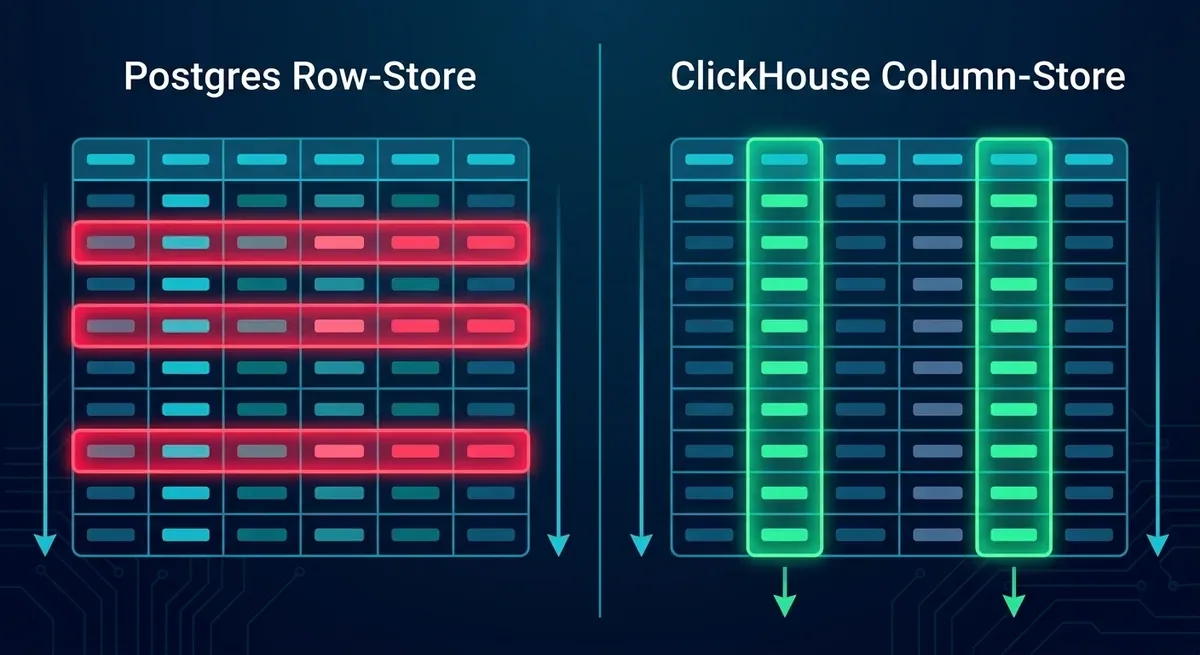
Để hiểu tại sao, bạn cần nhìn vào cách Postgres lưu dữ liệu. Postgres là row-store: mỗi row được lưu liền nhau trên disk. Khi bạn chạy một query kiểu SELECT date, SUM(amount) FROM transactions GROUP BY date, bạn chỉ cần 2 cột date và amount. Nhưng vì dữ liệu lưu theo row, Postgres vẫn phải đọc toàn bộ row bao gồm cả user_id, product_id, metadata, created_at, và hàng chục cột khác mà query không cần. Với 100 triệu dòng, EXPLAIN cho thấy hệ thống đang đọc gần 100GB dữ liệu cho một query mà thực tế chỉ cần vài GB.
B-tree index cũng không giúp được gì nhiều ở đây. Index hiệu quả cho point lookup tìm một user cụ thể, lấy một transaction theo ID. Nhưng khi bạn cần aggregate toàn bộ dataset hoặc scan range lớn, index gần như vô dụng, optimizer sẽ chọn sequential scan.
Materialized view thì giải quyết được một phần, nhưng lại tạo ra vấn đề mới: refresh chậm (với 100 triệu dòng, refresh mất vài phút), dữ liệu bị stale, và maintenance ngày càng phức tạp khi số lượng view tăng lên. Theo kinh nghiệm của mình, materialized view chỉ là giải pháp tạm khi data còn ở mức vài chục triệu dòng. Vượt qua ngưỡng đó, bạn cần một kiến trúc khác.
Column-store thay đổi hoàn toàn cuộc chơi
ClickHouse giải quyết bài toán này bằng một triết lý storage hoàn toàn khác: column-store. Thay vì lưu dữ liệu theo row, ClickHouse lưu từng cột riêng biệt trên disk. Nghe đơn giản, nhưng impact của nó lên analytics workload là cực kỳ lớn.
Quay lại ví dụ query SELECT date, SUM(amount) FROM transactions GROUP BY date. Trên ClickHouse, nó chỉ đọc đúng 2 cột date và amount, bỏ qua hoàn toàn tất cả các cột còn lại. Với 100 triệu dòng, thay vì đọc 100GB như Postgres, ClickHouse có thể chỉ cần đọc 2-3GB. Đó là lý do cốt lõi tạo ra sự khác biệt hàng trăm lần về tốc độ.
Nhưng columnar storage chỉ là một phần. ClickHouse còn có hàng loạt tối ưu khác dành riêng cho OLAP:
Vectorized execution thay vì xử lý từng row một, ClickHouse xử lý hàng nghìn giá trị cùng lúc trong một batch, tận dụng SIMD instruction của CPU hiện đại. Cái này nghe academic nhưng thực tế nó tạo ra throughput cực cao khi scan dataset lớn.
Sparse primary index ClickHouse không index từng row như B-tree. Nó tạo entry theo block (mặc định 8192 rows/block), giúp skip nhanh những block không liên quan mà không tốn overhead index quá lớn.
Compression theo cột vì dữ liệu cùng kiểu được lưu liền nhau, compression ratio cực cao. Cột status chỉ có vài giá trị distinct? Nén xuống gần như không đáng kể. Cột date? Pattern lặp lại rất đều, nén rất tốt. Kết quả: 100GB trên Postgres chỉ còn khoảng 18GB trên ClickHouse.
Mình thấy cái hay nhất của ClickHouse là nó không cố làm mọi thứ. Nó không hỗ trợ UPDATE/DELETE kiểu OLTP, không có foreign key, transaction support rất hạn chế. Nhưng đổi lại, nó làm analytics cực kỳ tốt. Đây là trade-off có chủ đích, và khi bạn hiểu rõ trade-off này, bạn sẽ biết cách dùng nó đúng chỗ.
Dựng pipeline CDC và kết quả benchmark
Một quyết định quan trọng nhất trong cả quá trình migration: không replace Postgres. Postgres vẫn là source of truth cho toàn bộ application logic. ClickHouse chỉ phục vụ analytics. Hai hệ thống chạy song song, mỗi cái làm đúng việc nó giỏi nhất.
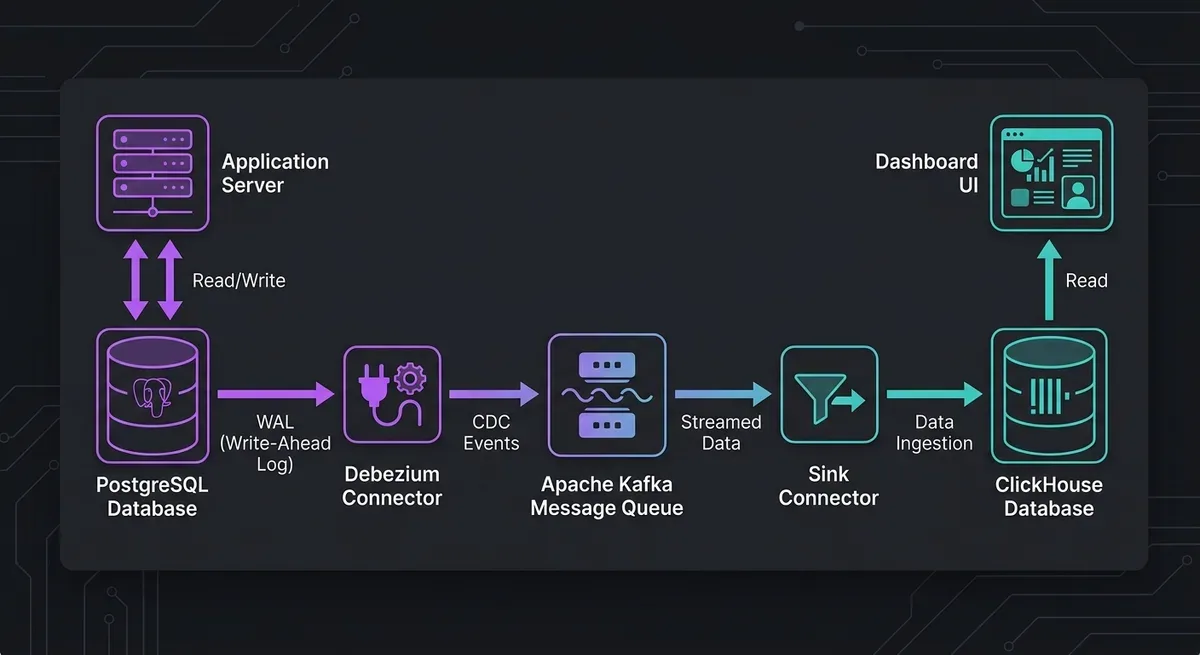
Pipeline replicate data từ Postgres sang ClickHouse được dựng bằng Debezium + Kafka:
- Application INSERT/UPDATE/DELETE bình thường trên Postgres
- Debezium đọc WAL (Write-Ahead Log) của Postgres, capture mọi thay đổi
- Event được đẩy vào Kafka topic
- Sink connector đọc từ Kafka và ghi xuống ClickHouse
Độ trễ end-to-end của pipeline này dưới 5 giây. Nghĩa là data trên ClickHouse chỉ trễ tối đa 5 giây so với Postgres hoàn toàn acceptable cho analytics dashboard.
Anh em lưu ý: Kafka ở đây không chỉ đóng vai trò transport. Nó còn là event buffer nếu ClickHouse hoặc sink connector gặp sự cố, event vẫn nằm trong Kafka và có thể replay lại. Điều này làm hệ thống resilient hơn rất nhiều so với việc replicate trực tiếp.
Bây giờ đến phần mọi người quan tâm nhất benchmark sau migration:
Con số nói lên tất cả. Nhưng mình muốn highlight thêm một điểm mà nhiều người hay bỏ qua: resource consumption. Postgres cần node 128GB RAM để chạy analytics workload (và vẫn chậm). ClickHouse chạy thoải mái trên node 16GB RAM cho cùng dataset. Storage giảm từ 100GB xuống 18GB nhờ columnar compression. Đây là tiết kiệm thực sự về infrastructure cost.
| Query | Postgres | ClickHouse | Speedup |
|---|---|---|---|
| Revenue by day | 47s | 0.3s | ~157x |
| Top products | 32s | 0.5s | ~64x |
| Percentile latency (p95, p99) | 18s | 0.2s | ~90x |
| Time-series rollup theo giờ | 25s | 0.4s | ~63x |
| Group by user | 41s | 0.6s | ~68x |
Phân tách workload pattern mình nghĩ team nào cũng nên biết
Nếu rút ra một bài học lớn nhất từ case này, đó là: đừng bắt một database làm hai việc khác bản chất. OLTP và OLAP là hai loại workload có yêu cầu hoàn toàn trái ngược nhau.
Khi bạn nhìn bảng này, bạn sẽ thấy rõ tại sao một database không thể tối ưu cho cả hai. Row-store giúp OLTP nhanh nhưng làm OLAP chậm. Column-store giúp OLAP nhanh nhưng làm OLTP chậm. Đây là trade-off ở tầng kiến trúc, không phải thứ bạn tune config để fix được.
| Đặc điểm | OLTP (Postgres) | OLAP (ClickHouse) |
|---|---|---|
| Pattern đọc | Point lookup, few rows | Full scan, aggregate millions of rows |
| Pattern ghi | Insert/update frequent | Bulk insert, append-only |
| Cần index | B-tree, per-row | Sparse, per-block |
| Storage layout | Row-store | Column-store |
| Transaction | ACID, strong consistency | Eventual consistency OK |
| Latency target | < 10ms per query | < 1s cho aggregate query |
Theo kinh nghiệm của mình, thời điểm nên bắt đầu nghĩ đến việc tách analytics workload là khi dataset analytics vượt quá 50 triệu dòng và dashboard bắt đầu chậm hơn 5 giây dù đã tuning. Nếu bạn đang ở mức vài triệu dòng, Postgres với materialized view vẫn ổn, chưa cần phức tạp hóa kiến trúc.
Một điểm nữa mình muốn chia sẻ: nhiều anh em hay hỏi "sao không dùng read replica của Postgres cho analytics?". Mình đã thử. Read replica giúp giảm load trên primary, nhưng bản chất vẫn là row-store, vẫn phải scan toàn bộ row. Query vẫn chậm y như trên primary, chỉ là không ảnh hưởng đến app nữa thôi. Nó giải quyết vấn đề contention, không giải quyết vấn đề performance.
Cuối cùng, nếu anh em đang cân nhắc migrate, mình khuyên là bắt đầu với một query chậm nhất trước. Dựng pipeline CDC cho đúng table đó, chạy song song cả Postgres và ClickHouse, so sánh kết quả. Khi đã validate được performance gain và data consistency, mới mở rộng ra các query còn lại. Đừng big bang migration rủi ro cao và khó rollback.
Code setup Debezium, config ClickHouse table engine (mình recommend MergeTree với ORDER BY theo các cột hay dùng trong WHERE/GROUP BY), và ví dụ query chạy được mình sẽ để ở phần comment cho anh em tiện tham khảo.
Nguyễn Nhật Long
@nguyennhatlong1303Nguyễn Nhật Long is a Senior Frontend Engineer and Frontend Team Leader with 7 years of experience building real-time fintech platforms. Specializing in React, Next.js, TypeScript, and React Native, shipping 10+ products across Web, Mobile, Telegram Mini-Apps, and Web3.
Thấy hay? Chia sẻ cho bạn bè!