OpenClaw + Ollama: Chạy AI Agent local, token free, ngủ ngon
OpenClaw ngốn token như uống nước. Kết hợp với Ollama chạy local, bạn có AI agent miễn phí mà vẫn giữ được quyền riêng tư.
Nguyễn Nhật Long
@nguyennhatlong1303
OpenClaw + Ollama: Chạy AI Agent local, token free, ngủ ngon
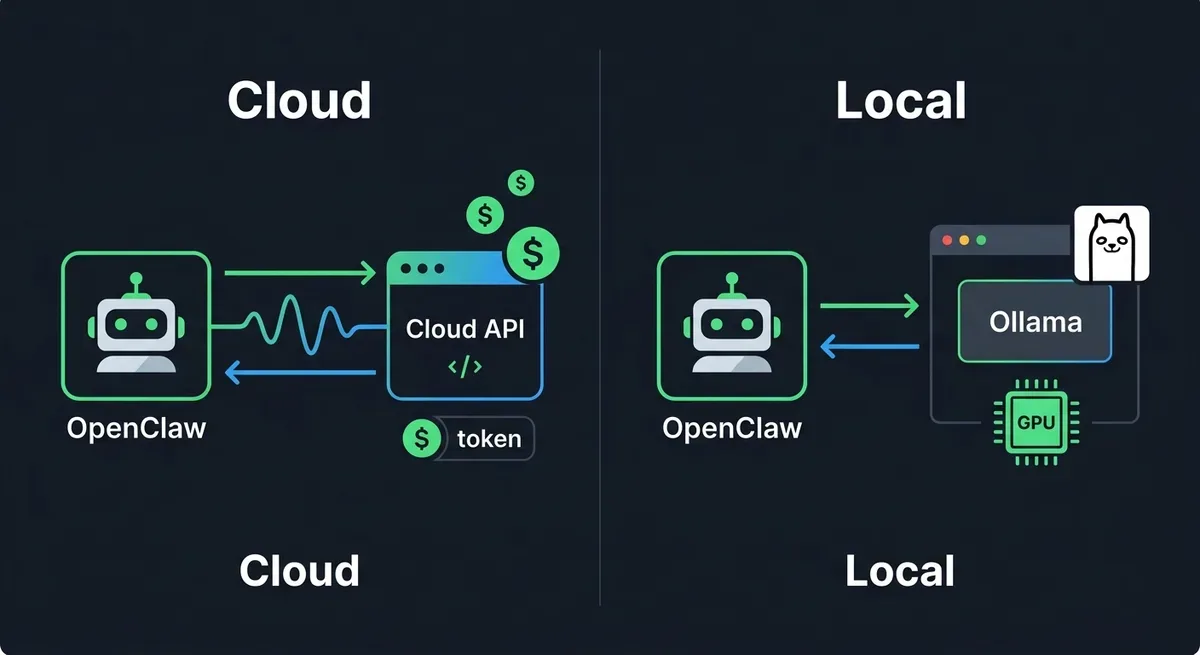
Mình từng để OpenClaw chạy với Claude Sonnet trong một buổi chiều, làm vài task refactor code. Tối về check billing gần $15 bay mất. Không phải vì model trả lời nhiều, mà vì cái context length cứ phình ra: system prompt nhồi workspace files, memory retrieval, tool calls, web reading... Mỗi request gửi đi là cả đống token đầu vào mà bạn không hề nhìn thấy.
Nếu bạn cũng đang dùng OpenClaw và cảm thấy ví mỏng dần, thì đây là combo mình đã chuyển sang: OpenClaw + Ollama, chạy hoàn toàn trên máy local.
Tại sao OpenClaw lại ngốn token đến vậy?
OpenClaw không đơn giản là gửi một prompt rồi nhận response. Nó là một agent framework nghĩa là mỗi lần bạn ra lệnh, nó sẽ:
- Đọc workspace files và config, nhồi vào system prompt
- Truy xuất memory từ các phiên trước
- Gọi tools (đọc file, chạy command, search web)
- Tóm tắt kết quả rồi tiếp tục loop
Mỗi bước đều tiêu token. Và context length cứ tích lũy qua mỗi vòng lặp. Theo kinh nghiệm của mình, một task phức tạp có thể ngốn 50K-200K tokens chỉ trong một session.
Để dễ hình dung, đây là bảng so sánh chi phí ước tính khi chạy OpenClaw trên cloud vs local:
Rõ ràng, nếu bạn không cần model khủng cho mọi task, thì chạy local là lựa chọn hợp lý hơn nhiều.
| Tiêu chí | Cloud API (Claude Sonnet) | Local (Ollama + Llama 3) |
|---|---|---|
| Chi phí input token | $3/1M tokens | $0 |
| Chi phí output token | $15/1M tokens | $0 |
| 10M input + 10M output/tháng | ~$180/tháng | $0 (chỉ tốn điện) |
| Privacy | Data gửi lên cloud | Data ở local 100% |
| Tốc độ | Phụ thuộc network + rate limit | Phụ thuộc GPU của bạn |
| Chất lượng output | Cao (model lớn) | Khá tốt với model 7B-13B |
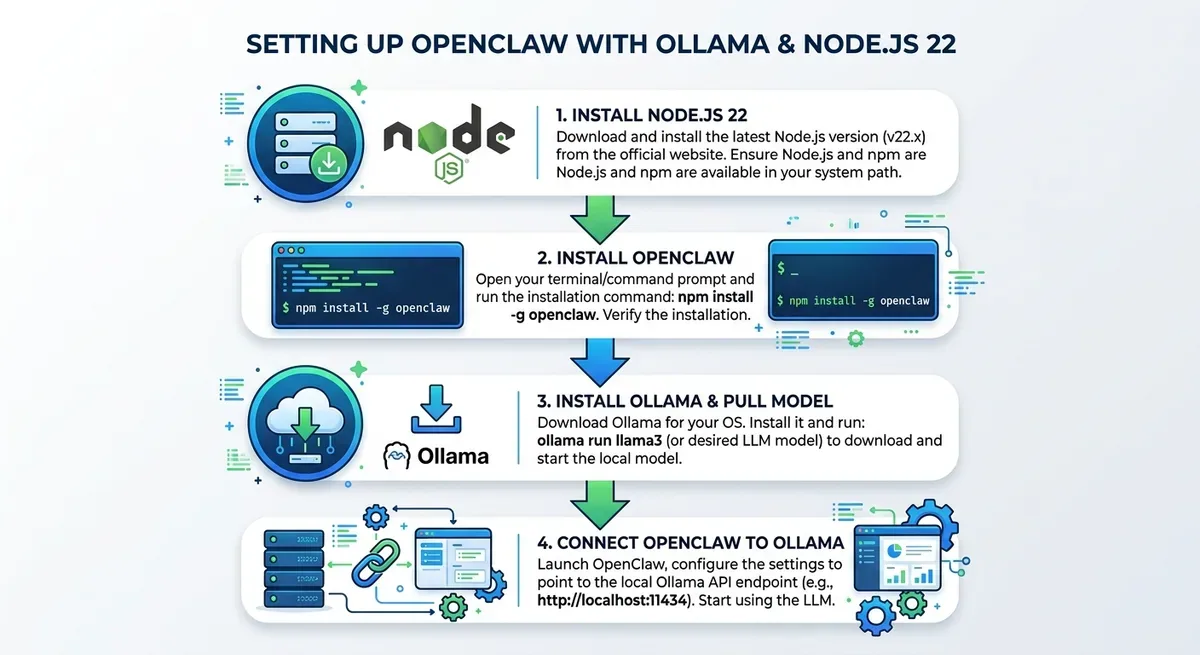
Setup OpenClaw + Ollama từ A đến Z
Bước 1: Chuẩn bị Node.js 22+
OpenClaw build trên Node.js và yêu cầu version 22 trở lên. Bạn có thể dùng nvm để quản lý version:
1nvm install 222nvm use 223node -v # Confirm v22.x
Hoặc nếu bạn trên macOS và thích GUI, có thể dùng ServBay để switch version nhanh mà không phải đụng vào biến môi trường.
Bước 2: Cài OpenClaw
bash:::curl -fsSLhttps://molt.bot/install.sh| bash openclaw onboard --install-daemon
Lệnh onboard sẽ tạo workspace, cài daemon chạy nền, và hướng dẫn bạn config ban đầu.
Bước 3: Cài Ollama và pull model
bash:::# Cài Ollama curl -fsSLhttps://ollama.com/install.sh| sh # Pull model chọn model phù hợp với RAM/VRAM của bạn ollama pull llama3 # 8B params, cần ~8GB RAM ollama pull deepseek-coder-v2:16b # Nếu máy mạnh hơn ollama pull mistral # Lựa chọn nhẹ, chất lượng ổn
Điều mình thấy hay là Ollama tự động detect GPU (NVIDIA, AMD, Apple Silicon) và optimize cho phù hợp. Trên MacBook M2 Pro 16GB của mình, model llama3 8B chạy khá mượt, tầm 30-40 tokens/s.
Bước 4: Kết nối OpenClaw với Ollama
1ollama launch openclaw
Lệnh này config OpenClaw trỏ về Ollama local thay vì cloud API. Từ giờ mọi inference đều chạy trên máy bạn.
Chạy local rồi, nhưng bảo mật thì sao?
Đây là phần nhiều người bỏ qua. OpenClaw là agent có quyền thực thi command trên máy bạn. Nó có thể đọc file, chạy script, thậm chí xóa thứ gì đó nếu hiểu sai instruction. Mình đã thấy case trên Twitter về việc OpenClaw xóa nhầm email đó không phải chuyện đùa.
Git là lưới an toàn số 1
Luôn init git cho workspace của OpenClaw:
1git init2git add AGENTS.md SOUL.md memory/3git commit -m "Init agent workspace"
Mỗi khi agent thay đổi config hay memory files, bạn có thể git diff để review, và git revert nếu có gì sai. Theo kinh nghiệm của mình, nên commit trước mỗi task lớn coi như tạo checkpoint trong game.
Chạy trong Docker container
Nếu bạn cho agent làm task phức tạp (install packages, modify system files), hãy chạy trong container:
1docker run -it --gpus all -v $(pwd)/workspace:/workspace ollama-openclaw
Agent có phá gì thì cũng chỉ phá trong container, máy host vẫn an toàn.
Không expose gateway ra public
OpenClaw có gateway service để nhận lệnh từ xa. Đừng bao giờ expose nó ra internet mà không có auth. Chạy openclaw doctor để check xem có lỗ hổng nào không. Nếu cần remote access, dùng VPN hoặc SSH tunnel.
Khi nào nên dùng cloud, khi nào nên local?
Mình không nói local là tốt nhất cho mọi trường hợp. Thực tế là:
Cách mình hay làm là dùng local cho 80% task hàng ngày (generate boilerplate, viết test, refactor nhỏ), và chỉ switch sang cloud API cho những task thực sự cần model mạnh. Kiểu như đi xe máy trong thành phố, chỉ gọi taxi khi cần đi xa.
| Use case | Nên dùng | Lý do |
|---|---|---|
| Code generation đơn giản, refactor | Local (Ollama) | Tiết kiệm, model 8B đủ tốt |
| Debug lỗi phức tạp, multi-file | Cloud (Claude/GPT-4) | Cần reasoning mạnh, context dài |
| Xử lý data nhạy cảm, code proprietary | Local (Ollama) | Privacy là ưu tiên số 1 |
| Prototype nhanh, thử ý tưởng | Local (Ollama) | Không lo chi phí, iterate thoải mái |
| Production-grade code review | Cloud | Chất lượng output cao hơn đáng kể |
Những điều cần nhớ
- OpenClaw ngốn token không phải vì model trả lời dài, mà vì agent loop + context accumulation. Hiểu điều này để không bất ngờ khi nhìn bill.
- Ollama + model 8B là đủ tốt cho phần lớn coding tasks hàng ngày. Không cần GPU xịn Apple Silicon hoặc một card NVIDIA tầm trung là chạy được.
- Git init workspace ngay từ đầu. Đây không phải best practice, đây là bắt buộc khi cho AI agent quyền thực thi.
- Đừng expose gateway ra public. Chạy
openclaw doctor, dùng VPN cho remote access. - Hybrid approach là thực tế nhất: local cho task thường, cloud cho task khó. Ví tiền sẽ cảm ơn bạn.
OpenClaw là một công cụ mạnh, nhưng mạnh mà không kiểm soát thì thành rủi ro. Kết hợp với Ollama chạy local, bạn vừa giữ được sức mạnh của agent framework, vừa không phải lo mỗi sáng mở email thấy invoice từ Anthropic. Chạy thử đi, rồi bạn sẽ thấy cái quạt GPU kêu to hơn một chút, nhưng ví thì im lặng hẳn.
Nguyễn Nhật Long
@nguyennhatlong1303Nguyễn Nhật Long is a Senior Frontend Engineer and Frontend Team Leader with 7 years of experience building real-time fintech platforms. Specializing in React, Next.js, TypeScript, and React Native, shipping 10+ products across Web, Mobile, Telegram Mini-Apps, and Web3.
Thấy hay? Chia sẻ cho bạn bè!