Uber đã trị database overload như thế nào: Từ rate-limiting tĩnh đến load manage
Uber giảm ~70% P99 latency nhờ chuyển từ quota-based rate limiting sang intelligent load manager sát storage layer. Bài học cho mọi hệ thống stateful database.
Nguyễn Nhật Long
@nguyennhatlong1303
Uber đã trị database overload như thế nào: Từ rate-limiting tĩnh đến load management thông minh
Hình dung thế này: bạn có hàng ngàn microservices, 170 triệu monthly active users, hàng chục petabyte data, và hàng chục triệu requests mỗi giây đổ vào database. Một spike nhỏ ở một góc hệ thống có thể gây timeout dây chuyền, retry chồng retry, rồi cả hệ thống sập domino. Đó chính xác là bài toán mà team database của Uber phải giải — và cách họ giải nó thì thật sự đáng học.
Mình vừa đọc xong bài engineering blog của Uber về hành trình xây dựng intelligent load manager cho database layer, và phải nói là có nhiều insight rất thực tế. Không phải kiểu "chúng tôi dùng AI xịn lắm" mà là những bài học đau thương từ production, từ việc chọn sai signal, đặt sai chỗ, đến khi tìm ra đúng approach.
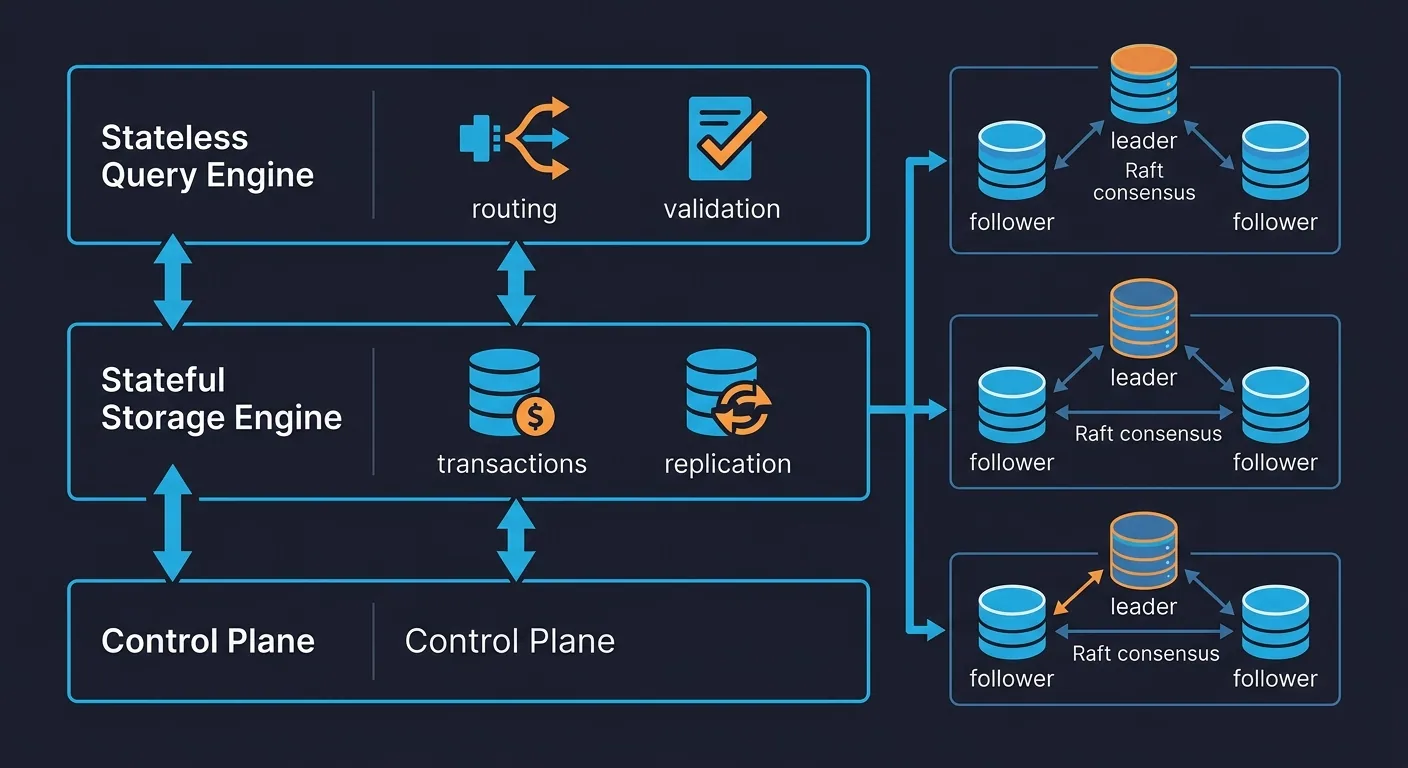
Kiến trúc database của Uber: Docstore và Schemaless
Trước khi đi vào phần hay, cần hiểu Uber dùng gì. Họ có hai hệ thống database tự build: Docstore (hỗ trợ full CRUD với transactions) và Schemaless (tối ưu cho append-only workloads). Cả hai đều chạy trên MySQL, span hàng ngàn clusters.
Kiến trúc gồm 3 layer chính:
- Stateless query engine: lo query planning, routing, sharding, schema management, authorization
- Stateful storage engine: lo transaction management, connection pooling, consensus (Raft), replication
- Control plane: quản lý toàn bộ
Data được shard ra nhiều partitions, mỗi partition có 1 leader + 2 followers, chạy Raft consensus, backed bởi MySQL trên NVMe SSDs.
Điều mình thấy hay là cách họ tách rõ stateless vs stateful layer — và chính sự phân tách này dẫn đến bài học quan trọng nhất của cả bài.
Lần đầu thất bại: Quota-based rate limiting ở query engine
Cách tiếp cận ban đầu nghe rất hợp lý: gán mỗi request một "capacity unit cost" dựa trên bytes processed, cấp cho mỗi user một quota cố định, trả 429 khi vượt quota. Vì query engine là stateless nên quota usage được lưu trong Redis.
Nghe đơn giản, sạch sẽ, đúng textbook. Nhưng production thì không care textbook.
Vấn đề 1: Thêm complexity không cần thiết. Mỗi request phải gọi Redis thêm một hop — thêm một single point of failure. Để stateless routing layer biết partition nào đang overload, nó phải track realtime health của hàng ngàn partitions. Overhead quá lớn.
Vấn đề 2: Cost model sai bét. Một query full table scan trả về 1 row bị tính cùng cost với query chỉ đọc đúng 1 row. Đây là lỗi fundamental — lightweight và heavyweight operations bị đối xử như nhau, khiến quota enforcement vô nghĩa.
Vấn đề 3: Quota tĩnh, thế giới thì động. Quota được define cứng, team nào cũng liên tục xin tăng quota. Trong môi trường multitenant, cách này không scale được.
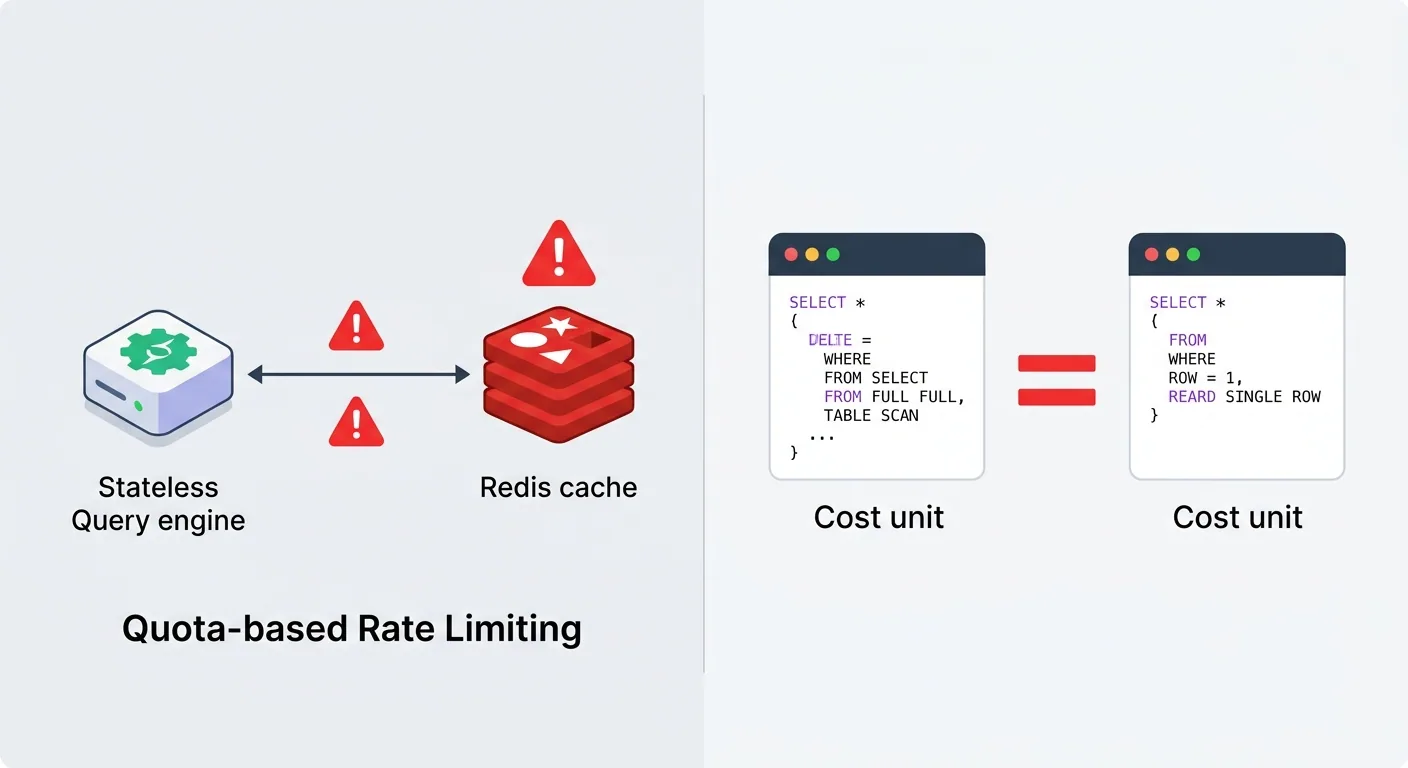
Theo kinh nghiệm của mình, đây là pattern rất phổ biến: chúng ta hay đặt protection ở chỗ tiện nhất (stateless layer, gateway, proxy) thay vì chỗ đúng nhất. Uber cũng vậy, và họ rút ra insight quan trọng: overload management phải sống càng gần storage nodes càng tốt.
Chọn đúng signal: Không phải QPS, mà là concurrency
Đây là phần mình thích nhất. Khi thiết kế load manager, câu hỏi đầu tiên là: dùng signal gì để biết hệ thống đang overload?
Cách phổ biến nhất là QPS-based rate limiting — quá N requests/giây thì reject. Nhưng cách này quá thô. Nó không phân biệt được request nhẹ vs request nặng, không account cho workload variability.
Uber chọn concurrency — số lượng operations đang in-flight tại một thời điểm. Và lý do thì rất elegant, dựa trên Little's Law:
1Concurrency = Throughput × Latency
Concurrency phản ánh trực tiếp system load. Khi latency tăng (dấu hiệu overload), concurrency tự động tăng theo dù throughput không đổi. Khi system healthy, cùng throughput đó concurrency sẽ thấp hơn.
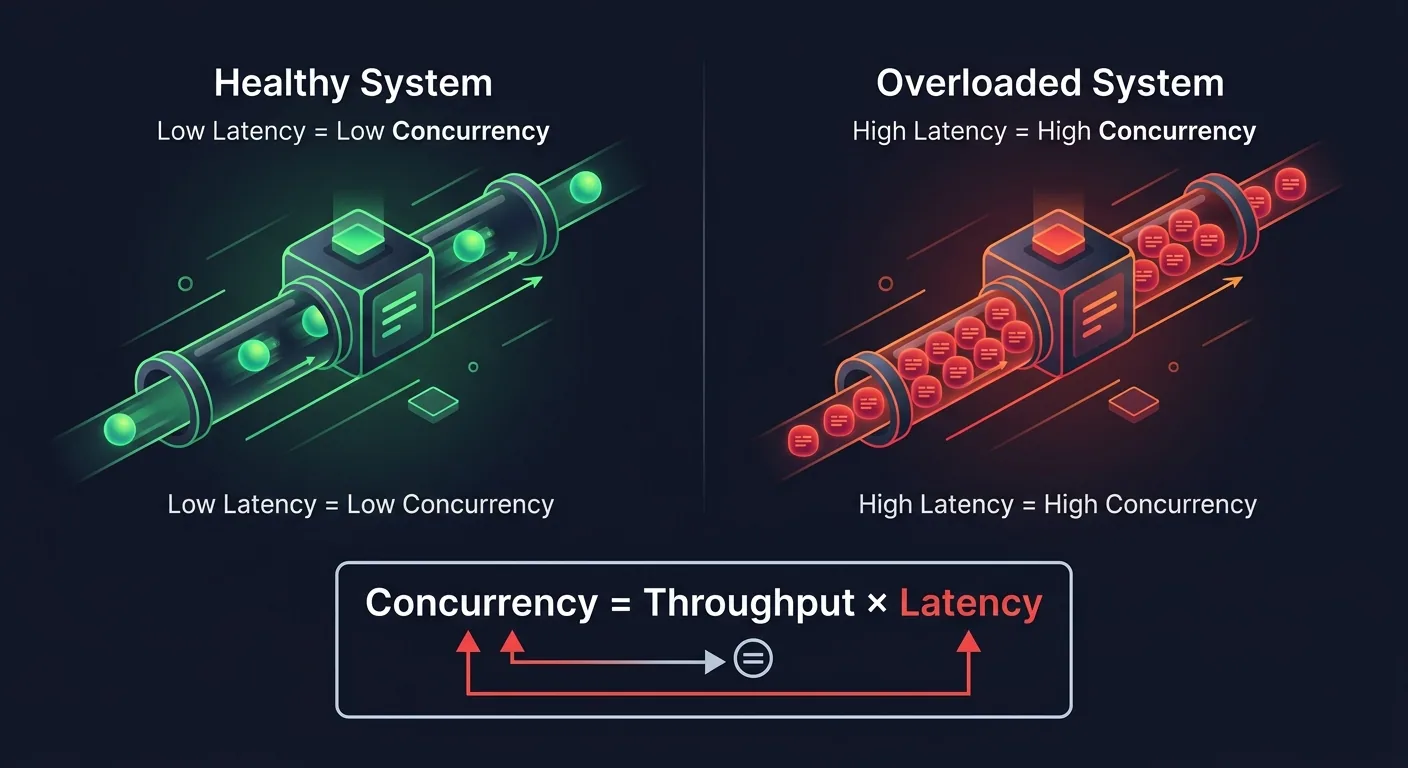
Điều này có ý nghĩa thực tế rất lớn: thay vì phải tune một con số QPS cứng cho mỗi workload (mà bạn gần như không bao giờ tune đúng), bạn dùng concurrency — nó tự adapt theo tình trạng thực tế của system. Query nặng chiếm concurrency nhiều hơn, query nhẹ chiếm ít hơn. Tự nhiên fair.
Intelligent load manager: Đặt đúng chỗ, dùng đúng signal
Kết hợp hai bài học trên, Uber xây intelligent load manager ngay trong stateful storage engine layer — sát MySQL nhất có thể. Load manager này:
- Detect overload từ multiple signals, không chỉ một metric đơn lẻ. Concurrency là signal chính, nhưng kết hợp với các signals khác để có cái nhìn toàn diện.
- Shed load thông minh — không phải reject bừa mà biết request nào nên drop trước, đảm bảo fairness trong môi trường multitenant.
- Adapt dynamically — không cần ai ngồi tune threshold thủ công.
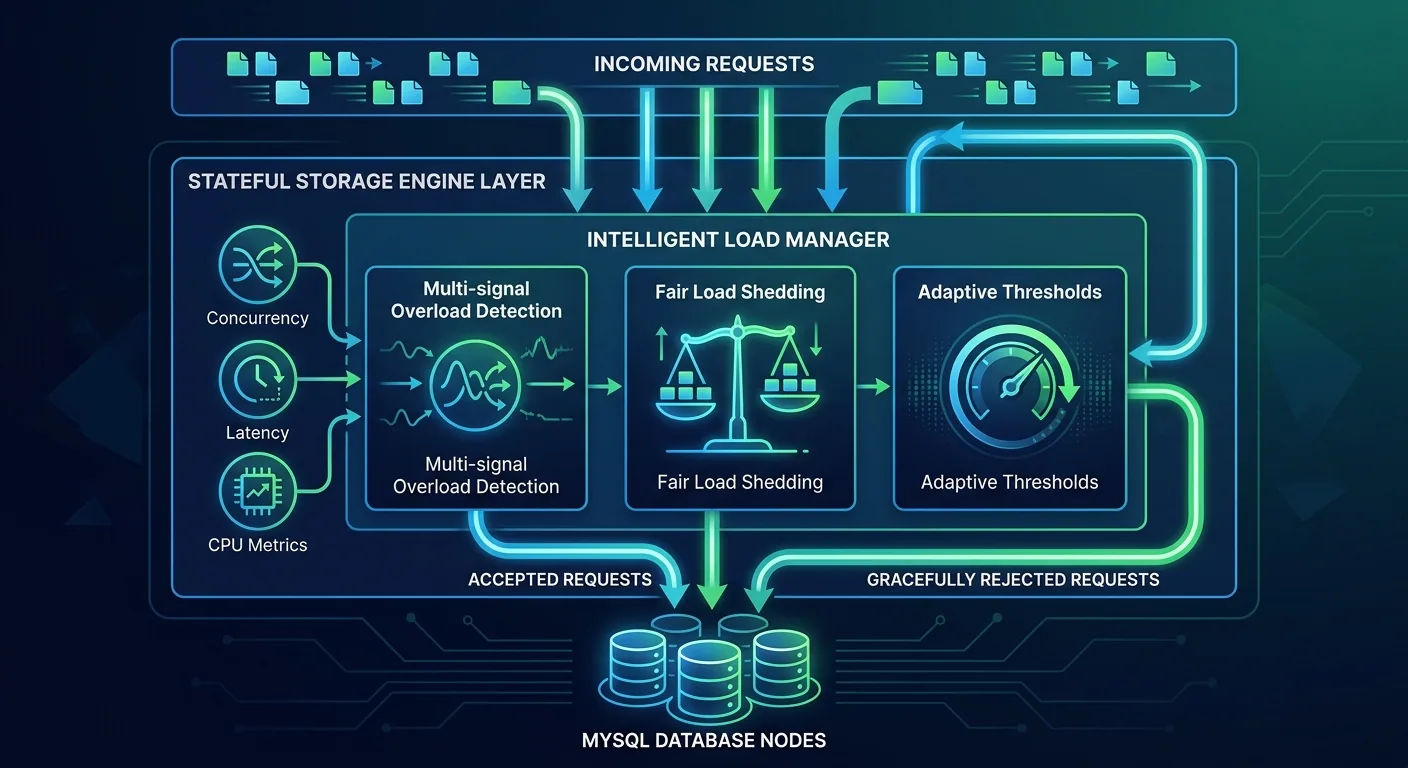
Kết quả? Giảm ~70% P99 latency. Đọc lại cho rõ: bảy mươi phần trăm. Đó không phải optimization nhỏ, đó là thay đổi fundamental.
Những bài học mình rút ra
Đặt protection đúng chỗ quan trọng hơn protection đúng cách. Rate limiting ở gateway hay stateless layer nghe hợp lý nhưng thiếu context. Càng gần resource cần bảo vệ, bạn càng có nhiều thông tin để ra quyết định đúng.
Concurrency > QPS cho stateful systems. Nếu bạn đang dùng QPS-based rate limiting cho database, hãy cân nhắc chuyển sang concurrency-based. Little's Law không nói dối — concurrency phản ánh load thực tế tốt hơn nhiều.
Static quotas không work trong multitenant. Mình đã thấy pattern này ở nhiều công ty Việt Nam: cấp quota cứng, rồi cứ mỗi lần traffic tăng lại phải xin tăng quota. Adaptive approach tốn effort ban đầu nhưng tiết kiệm rất nhiều operational cost về sau.
Cost model phải phản ánh đúng resource consumption. Nếu một full table scan và một point read bị tính cùng giá, mọi rate limiting đều vô nghĩa. Đây là lỗi subtle mà rất nhiều team mắc phải.
Overload protection trong distributed systems không phải bài toán một chiều. Không có một metric thần thánh nào. Multiple signals, combined intelligently, luôn tốt hơn single signal.
Áp dụng được gì?
Không phải ai cũng có scale như Uber, nhưng principles thì universal. Nếu bạn đang chạy bất kỳ stateful system nào — dù là PostgreSQL, MongoDB, hay MySQL — và đang gặp vấn đề overload, hãy tự hỏi:
- Protection layer của mình đang ở đâu? Có đủ gần resource không?
- Mình đang dùng signal gì? QPS hay concurrency?
- Thresholds có đang được tune thủ công không? Có cách nào adaptive hơn?
Đôi khi câu trả lời không phải là thêm một layer mới, mà là đặt lại layer cũ cho đúng chỗ. Uber mất một lần fail với quota-based approach mới tìm ra điều đó. Hy vọng bạn không phải lặp lại sai lầm tương tự. 🚀
Nguyễn Nhật Long
@nguyennhatlong1303Nguyễn Nhật Long is a Senior Frontend Engineer and Frontend Team Leader with 7 years of experience building real-time fintech platforms. Specializing in React, Next.js, TypeScript, and React Native, shipping 10+ products across Web, Mobile, Telegram Mini-Apps, and Web3.
Thấy hay? Chia sẻ cho bạn bè!


